
文本视频搜索 Text-to-Video Retrieval
by Ying Zhang
文本视频搜索 Text-to-Video Retrieval
前言
文本视频搜索(Text-to-Video Retrieval)是指给定一句文本描述,在视频库中查找相应视频。与图像文本匹配(Image-Text Matching)相似,研究者们致力于探索如何更好地度量文本和视频之间的相似性。然而相较于文本图像搜索,一方面视频数据采集标注和存储难度大,目前人工标记的高质量数据集较少;另一方面视频内容复杂多变、时长变化大、处理难度高,研究工作的进展也相对较慢。

相关工作介绍
基于深度学习的文本视频搜索研究主要围绕两个思路来进行,一是如何融合视频的多模态特征,如利用图像,音频,动作等信息来学习更强大的视频特征;二是如何更有效地编码视频和文本特征,如采用不同类型的特征编码网络来学习互补特征。
[1] Learning Joint Embedding with Multimodal Cues for Cross-Modal Video-Text Retrieval, ICMR2018. [pdf] [code]
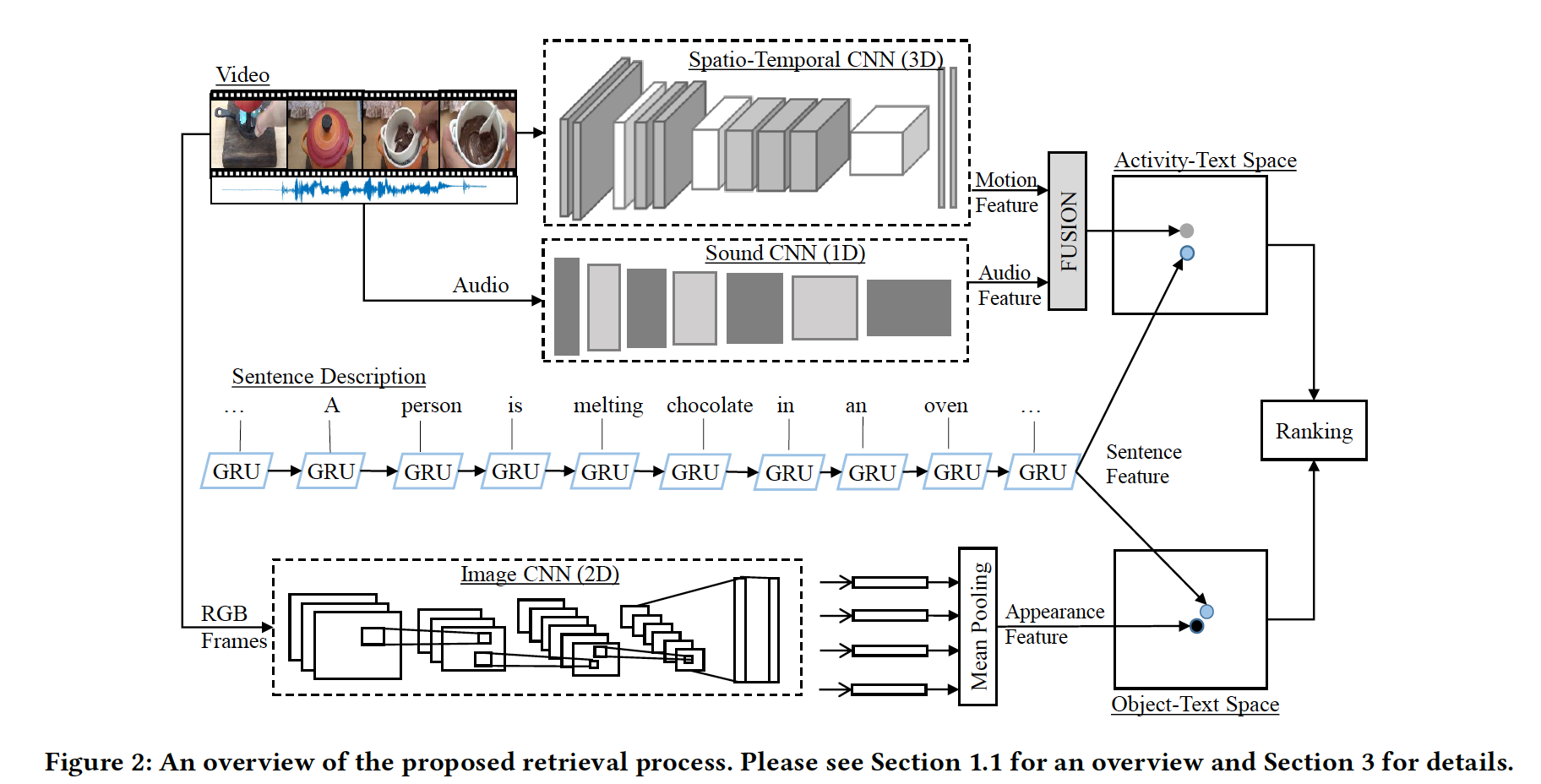
该文基本思路是结合视频不同模态输入与文本的相似度来提升搜索性能。该文将视频的 Activity Feature (RGB-I3D) 和 Audio Feature (SoundNet CNN) 相融合来学习 Activity-Text 联合特征空间,并采用 Object Feature (ResNet152) 来学习 Object-Text 联合特征空间,其中文本特征采用 word embeddings 300 + GRU 进行学习。此外,采用加权排序损失函数 (weighted ranking loss)并选取最难负样本 (hardest negatives) 来提升算法性能。
[2] Learning a Text-Video Embedding from Incomplete and Heterogeneous Data, arXiv2020. [pdf] [code]
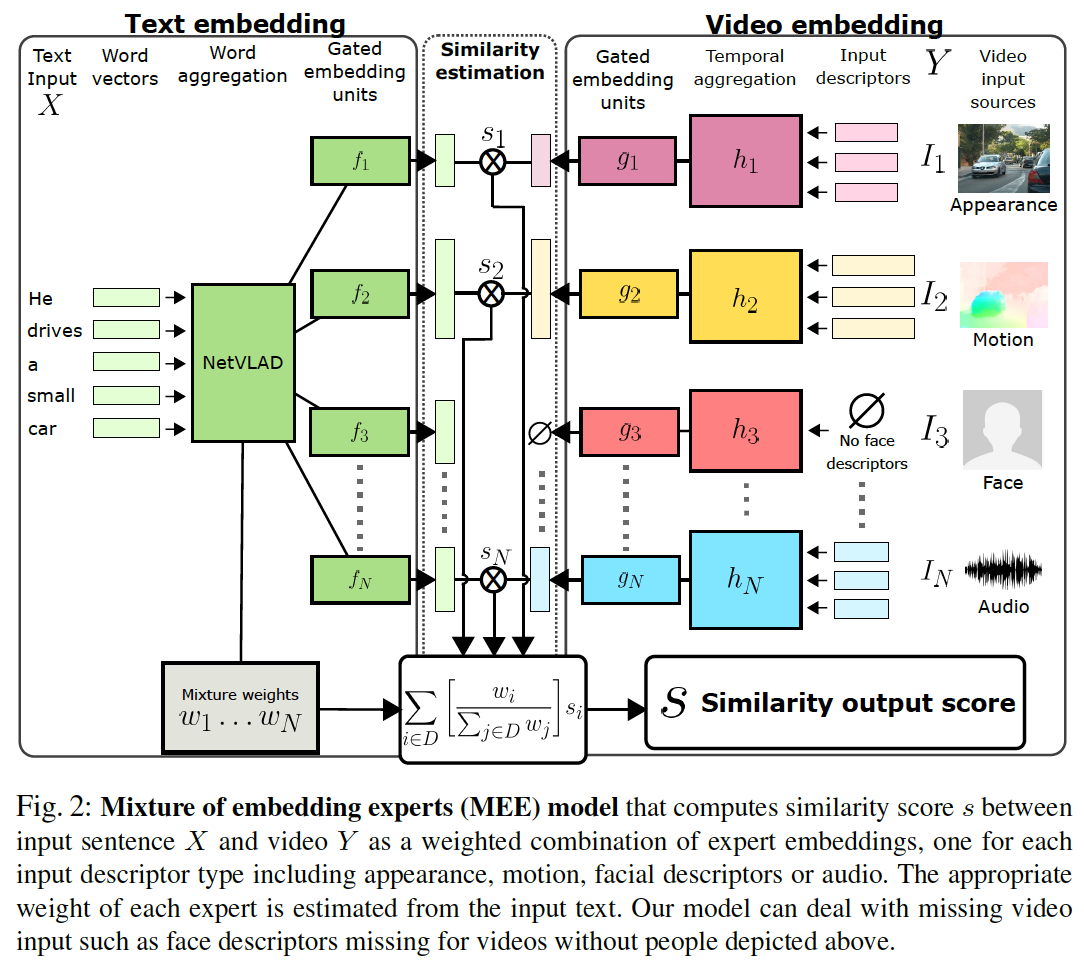
该文基本思路是针对视频的每种输入特征学习单独的专家嵌入模型(expert embedding model),并由输入文本在线学习权重来融合多个专家模型预测出的相似度得分,从而提升搜索性能。每个专家嵌入模型由 Gated embedding module 实现,采用 self-gating 机制来重新校准不同维度的激活值,强化不同模型学习到特征嵌入的差异。该文强调了该算法可以处理不完整的输入视频特征,当缺少某种输入特征时,对可计算的权重进行重新归一化即可。该文用到的视频输入特征包括:
- appearance features (ResNet-152 pre-trained on ImageNet)
- motion features (I3D pre-trained on Kinetics)
- audio features (audio CNN)
- face descriptor (dlib for face detection and recognition)。
针对文本输入,采用 word2vec trained on Google News 提取单词特征, NetVLAD 编码句子特征。
[3] Use What You Have: Video Retrieval Using Representations From Collaborative Experts, BMVC2019. [pdf] [code]
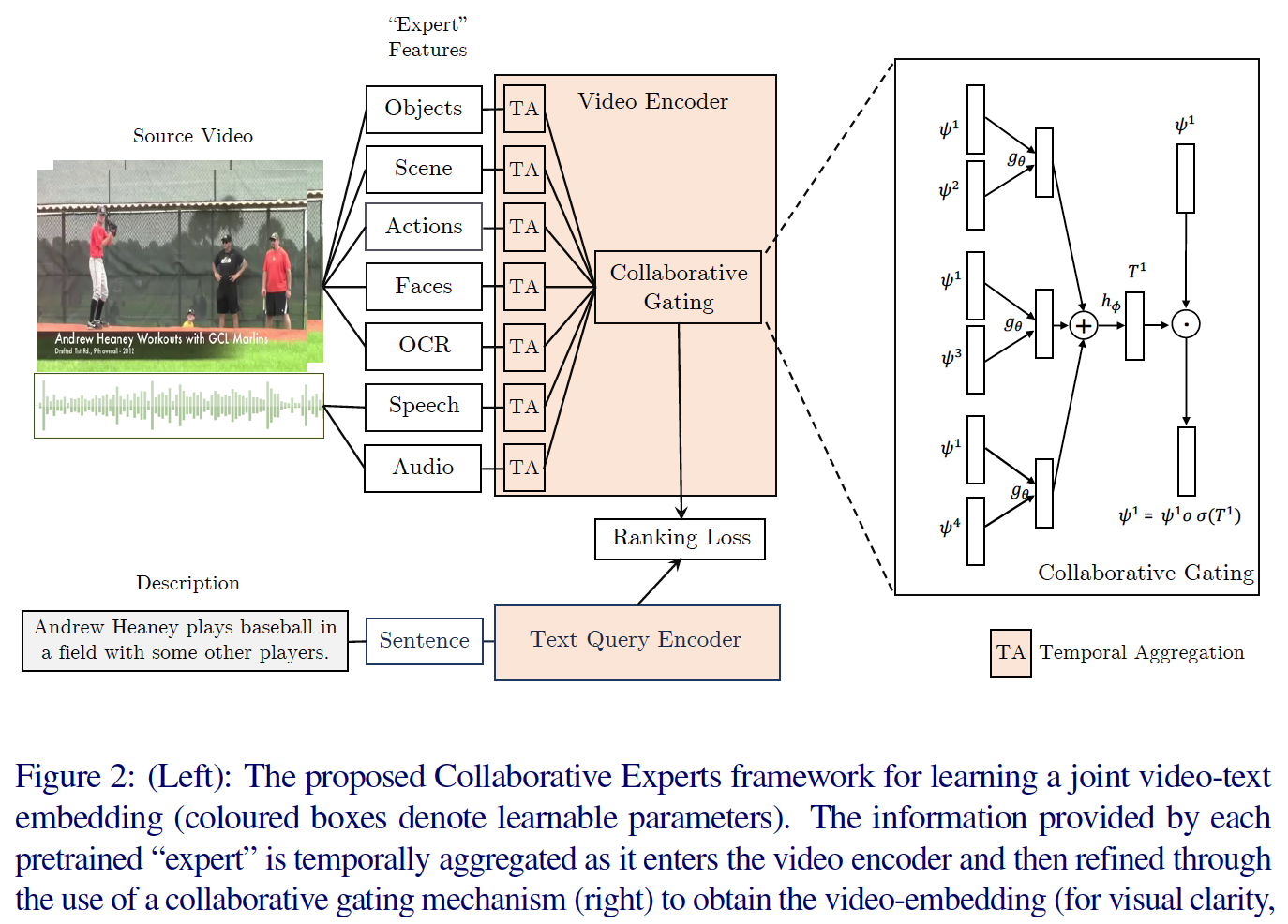
该文基本思路也是融合多种视频信息来学习更强大的视频表示。与上一篇类似,该文提出 Collaborative Gating,通过建模不同输入信息之间的关联来帮助学习多门限下的视频特征嵌入,并将多种特征嵌入相拼接作为最终的视频表示。该文采用的视频输入特征包括:
- object features (SENet-154 pretrained on ImageNet)
- motion features (I3D-inception)
- face features (SSD face detector + ResNet50 pretrianed on VGGFace2)
- audio features (VGGish pretrained on YouTube-8m)
- Speech-to-Text features (Google Cloud speech API + word2vec trained on Google News)
- OCR (Pixel Link for text detection + CNN pretrianed on Synth90K + word2vec trained on Google News)。
针对文本,采用 word2vec trained on Google News 提取单词特征,OpenAI-GPT 来提取上下文关联的单词特征,NetVLAD 编码句子特征。
[4] Dual Encoding for Zero-Example Video Retrieval, CVPR2019. [pdf] [code]
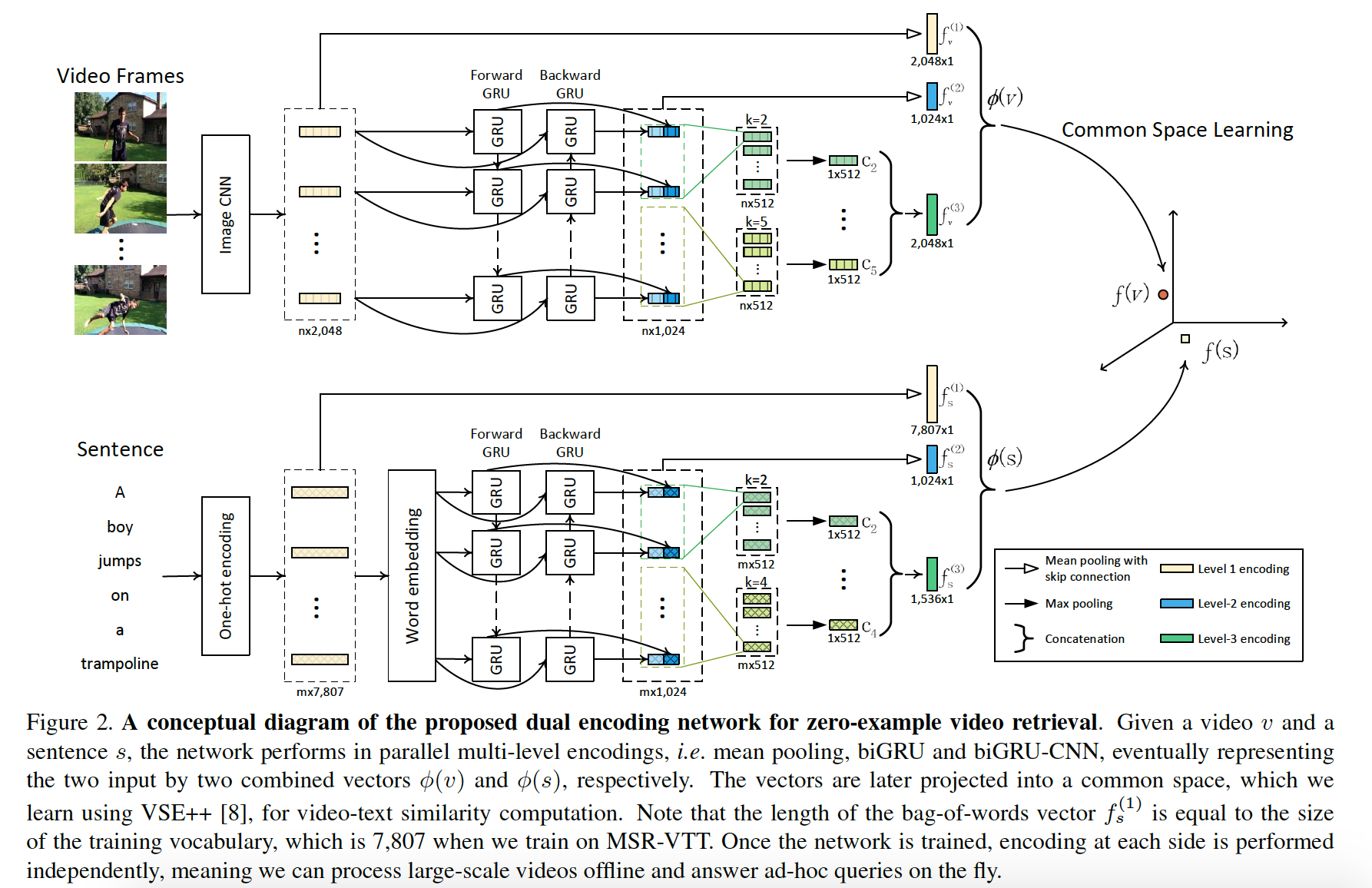
该文主要思路是对视频输入和文本输入分别进行多层编码:基于Mean Pooling 的全局编码,基于 BiGRU 的时序编码,强化局部信息的 BiGRU-CNN 编码,将多层编码特征相拼接作为输出特征。该文采用 ResNet-152 pre-trained on ImageNet 作为视频输入特征。针对文本,采用 word2vec pretrained on Flickr English tags 提取单词特征。
[5] Polysemous Visual-Semantic Embedding for Cross-Modal Retrieval, CVPR2019. [pdf] [code]
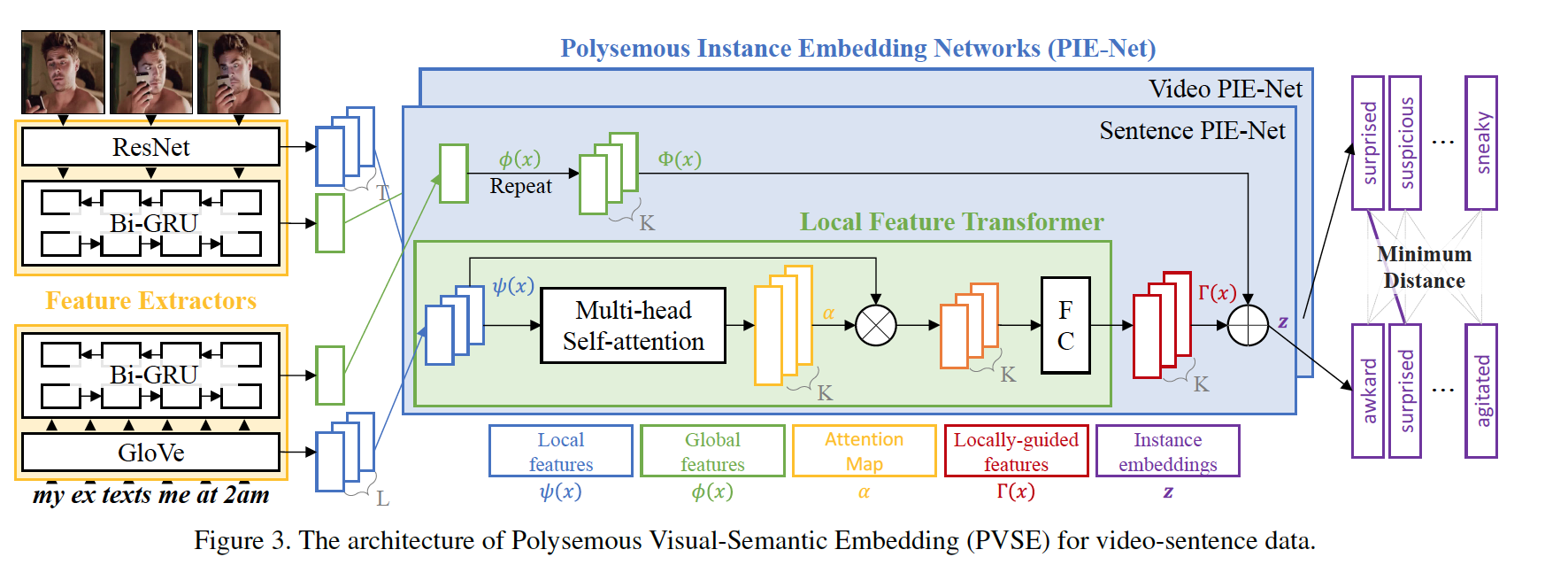
该文基本思路是利用 multi-head self-attention+ residual module 学习 K 种 attention 加权的视频和文本特征,并采用 multiple-instance learning 来改进排序损失函数。该文提出 Diversity Loss 来强化不同权重融合后特征的差异性,以及 Domain Discrepancy Loss 来约束学习到的文本和视频特征分布相近。
针对视频输入,该文采用 ResNet-152 pre-trained on ImageNet 提取图像特征, BiGRU 编码视频特征;针对文本输入,采用 GloVe pretrained on CommonCrawl 提取单词特征,BiGRU 编码句子特征。
此外,该文提出了 MRW (my reaction when) 数据集,包括 50,107 个视频-文本数据对,视频内容为给定文本的动作或情绪反应。该数据集划分为 44,107 个训练片段,1,000 个验证片段,和 5,000 个测试片段。
[6] A Joint Sequence Fusion Model for Video Question Answering and Retrieval, ECCV2018. [pdf] [code]
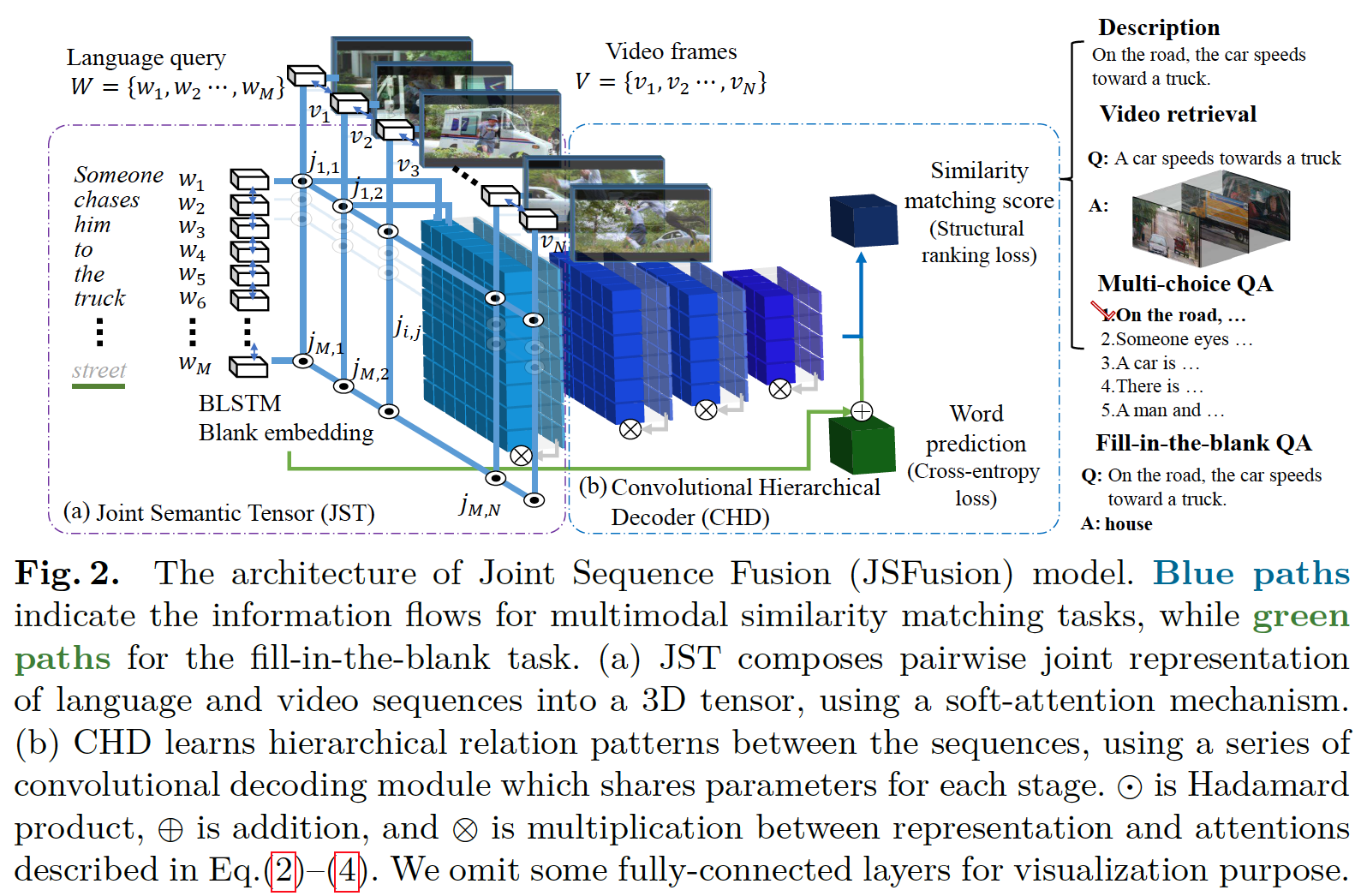
该文提出 JSFusion (Joint Sequence Fusion) 模型学习文本序列和视频序列的联合 3D 特征,CHD (Convolutional Hierarchical Decoder) 模型计算两个序列的匹配得分,可用于 retrieval 和 VQA 任务。针对视频输入,该文采用 ResNet-152 pre-trained on ImageNet 提取图像特征,VGGish + PCA 提取音频特征;针对文本输入,该文采用 glove.42B.300d 提取单词特征。
[7] Fine-Grained Action Retrieval Through Multiple Parts-of-Speech Embeddings, ICCV2019. [pdf] [code]
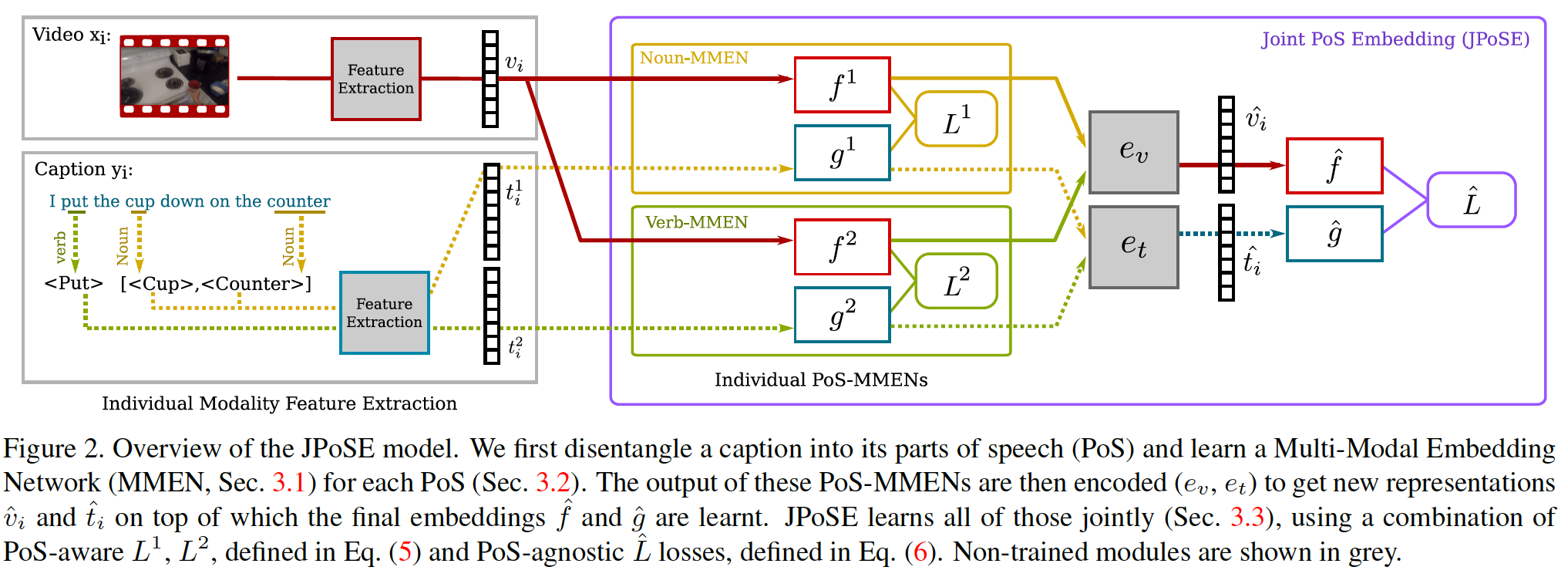
该文基本思路是利用 part-of-speech (PoS) parsing 对句子进行词性划分,针对每种词性(如名词,形容词,动此)学习相应的联合特征嵌入空间。针对视频输入,该文采用 TSN BNInception pretrained on Kinetics 提取时空特征;针对文本输入,该文采用 Word2Vec pertained on Wikipedia corpus 来提取单词特征。
常用数据集
-
MSR-VTT 由微软亚洲研究院在 CVPR2016 上针对 video captioning 任务提出,该数据集包含 10K 个视频片段,总时长约 41.2h,每个片段约 20 个文本描述,共有 200K 个视频文本数据对。数据集划分为 6513 个训练视频,497 个验证视频,和 2990 个测试视频。
-
MSVD 在 NAACL-HLT 2011 上提出,在 NAACL-HLT 2015 上用于 video captioning,该数据集包含 1970 个视频片段,每个视频由一种或多种语言描述。该文对每个视频选取大约 40 个英文描述,并将数据集划分为1200 个训练视频,100 个验证视频,和 670 个测试视频。
-
LSMDC 2016 来自 Large Scale Movie Description Challenge,相应论文发表在 IJCV2017。该数据集融合了 M-VAD(Arxiv2015)和 MPII-MD(CVPR2015)数据集,包含 200 部电影,总时长约147 h,共计 128,085个视频片段,和 128,118 个文本描述/台词。该数据集划分为 101,046 个训练片段和 7408 个验证片段。
- 其它数据集,包括 TGIF,MRW 和 EPIC 等。
- 相关任务的数据集如 DiDeMo,ActivityNet Captions, TACoS,Charades-STA,HowTo100M,VATEX 等。
总结
近年来文本视频搜索研究受到越来越多研究者的关注,实验结果表明,融合多种视频信息和多种网络编码结果可以帮助学习表达能力更强的联合特征,从而提升搜索性能。尽管有一些进展,其挑战依然存在:
- 如何保证实验结果的可对比性。从以上介绍的几篇论文可以看出,几乎每篇论文都采用了不同的视频输入特征或文本输入特征,难以保证算法对比的公平性。
- 如何保证视频和文本的标记质量。目前的文本视频数据集存在问题:
- “不完全适合”搜索任务:很多数据集是针对 video captioning 任务标记,一句文本描述会对应多个符合描述的视频,在搜索评测时会存在真值误差;
- 文本质量欠佳:一些视频对应的文本描述可能是通过自动语音识别获得,并不能准确表达视频内容,且存在较大误差,影响学习到模型的准确性;
- 视频质量欠佳:分辨率不一致,拍摄抖动,场景、目标、事件不连续,以及与内容无关的转场特效等。
- 不完全对齐:一些标记文本仅对应部分视频内容,同一视频对应的文本标记相差较大。
- 如何更好地编码视频信息和文本信息。
- 目前常用的编码方式是 mean pooling,BiGRU, NetVLAD,或 multi-head attention。在同样输入情况下不同的编码方式并不能带来明显提升。如何更好的捕捉序列特征仍是值得进一步研究的问题。
- 考虑到原始视频数据的处理难度较大,目前常用策略是预先提取视频的图像特征或动作特征,仅学习联合特征空间的映射函数。这在一定程度上会造成视频原始信息的损失,限制了算法性能。
- 如何更好地利用相关任务来帮助理解视频内容和文本信息,如视频分类,视频目标检测,视频动作检测,人脸检测与识别,场景分类等。
除此之外,目前研究者们也致力于提出数据量更大、内容更广泛的数据集如 HowTo100M,来帮助文本视频表征学习,可以有效提升下游相关任务的性能。同时我们也看到,难的不是收集视频,而是获取准确的人工标记。因此,如何根据海量视频自带的信息(如标题/副标题/字幕/语音/背景音乐/人物等)来学习理解视频内容值得进一步探索。当然,这也是一项更复杂更庞大的工程。